Prepoznavanje znakovnog jezika
Autori:
Zlata Stefanović, učenica III razreda Matematičke gimnazije u Beogradu
Vladan Bašić, učenik IV razreda Gimnazije u Kraljevu
Mentori:
Aleksa Račić, Elektrotehnički fakultet u Beogradu
Apstrakt
U ovom radu predstavljen je sistem za prepoznavanje američkog znakovnog jezika (ASL) na osnovu slike šake. Korišćeni su različiti pristupi klasifikaciji: k-Nearest Neighbours (kNN), klasifikacija ključnih tačaka (Keypoint Classification), konvoluciona neuronska mreža (CNN), kao i unapređena duboka mreža EfficientNetB3. Podaci su dobijeni iz sintetički generisane baze ASL znakova. Primenjene su različite metode pretprocesiranja i augmentacije kako bi se povećala robusnost modela. Postignuta tačnost varira između 56% i 99%, pri čemu je EfficientNetB3 pokazala najbolje rezultate.
Abstract
This paper presents a system for recognizing American Sign Language (ASL) signs from hand images. Various classification approaches were implemented, including k-Nearest Neighbours (kNN), Keypoint Classification, Convolutional Neural Networks (CNN), and the advanced deep learning model EfficientNetB3. The data used came from a synthetically generated ASL sign dataset. Several preprocessing and augmentation techniques were applied to improve model robustness. The achieved accuracy ranged from 56% to 99%, with EfficientNetB3 yielding the best results.
1. Uvod
Znakovni jezik predstavlja najčešće korišćen oblik neverbalne komunikacije među gluvo-nemim osobama. Ovaj vid izražavanja omogućava prenos informacija bez upotrebe govora, isključivo putem pokreta i gestikulacije. Međutim, znakovni jezik nije poznat široj populaciji što otežava njegovo razumevanje. Da bi se prevazišao ovaj problem, predloženo je korišćenje savremene tehnologije.
Značajan broj istraživanja je urađeno na ovu temu. Rad 1 prikazuje povećavanje dubina ConvNet-a sa jako malim (3x3) konvolucionim filterima. U radu 2 je razmatran Indijski Znakovni Jezik (ISL), gde je urađena detekcija, praćenje i binarizacija šake na osnovu boje kože nakon čega je korišćen grid za pronalaženje obeležja. Gestikulacije su klasifikovane kNN algoritmom. Rad 3 je fokusiran na detektovanje položaja u kojima nije pokazan nijedan znak koristeći Novelty Detection.
2. Metod
2.1. Baza podataka
Američki znakovni jezik (ASL) je najrasprostranjeniji znakovni jezik u svetu. Sastoji se od 26 znakova, za svako od 26 slova engleskog alfabeta, od kojih dva sadrže pokret, slovo J i slovo Z.
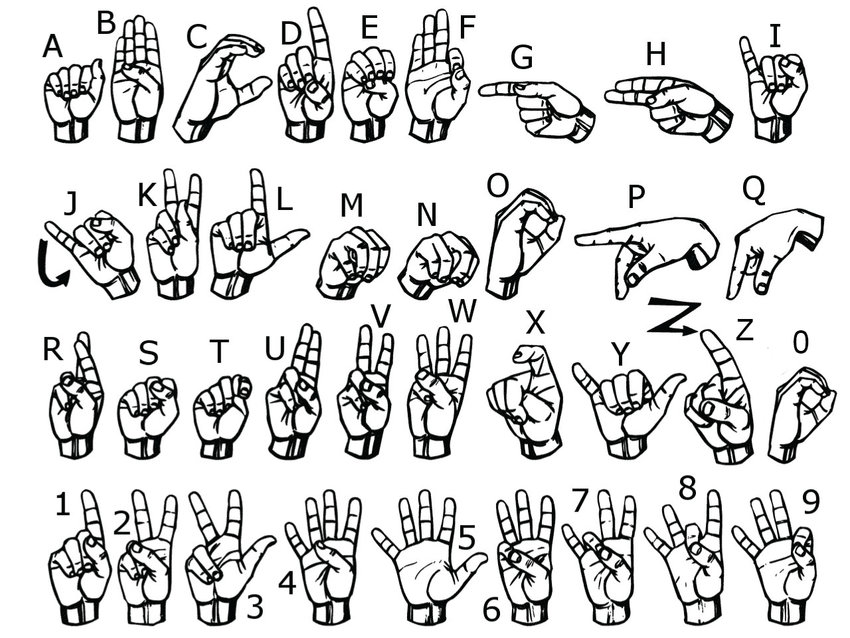
Za bazu podataka korišćena je baza sintetički generisanih slika američkog znakovnog jezika 4. Korišćena je sintetička baza zbog velikog broja slika različitih pozadina, osvetljenja i boja kože u nadi da će modeli, kao posledica veće raznovrsnosti, biti više robusni. Primenjena je ista podela na trening i test podatke kao kod autora baze.
2.1.1. Pretprocesiranje
Svaka slika je pre klasifikacije izmenjena na nekoliko načina. Na svakoj slici su primenjene sledeće transformacije:
- rotacija a za do $\pm$ 25%
- širenje po x-osi za do 30%
- širenje po y-osi za do 30%
- zumiranje za do 30%
- U 50% slučajeva preslikavanje u odnosu na vertikalu

2.1.2. Obrada baze za kNN
Klasifikacija znakova je realizovana prvo kroz određivanje pozicije šake. Za olakšanje ovog procesa pronađena je 21 ključna tačka šake (ukupno 42 koordinate) pomoću MediaPipe Holistic Pipeline-a 5.
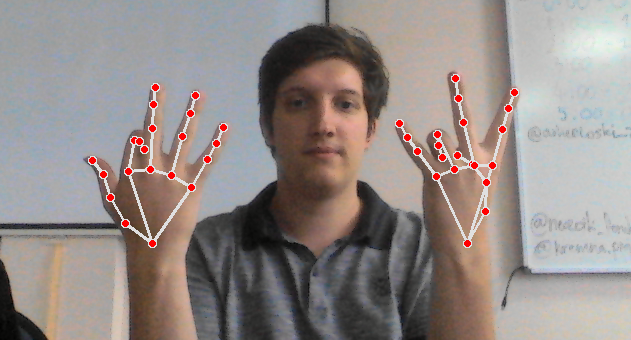
Prvi pristup za utvrđivanje boje kože je uzimanje srednje vrednosti izračunate iz 21 tačke, pri čemu su dobijeni neprecizni rezultati. Drugi način predstavlja određivanje koordinate sredine šake i uzimanje njene vrednosti, što nije dalo dobre rezultate jer se često nalazila senka na tom delu slike. Konačni i najprecizniji način je bio uzimanje celog opsega ovih tačaka. Na osnovu HSV vrednosti u koordinatama ključnih tačaka određen je opseg takav da je najmanji moguć a da u njega i dalje spadaju sve HSV vrednosti ključnih tačaka:
$$HSV_{min} = min(kp_{1},kp_{2},…,kp_{n})$$ $$HSV_{max} = max(kp_{1},kp_{2},…,kp_{n})$$
Na osnovu dobijene pozicije šake, slika je isečena oko nje i preoblikovana na 512 x 512 piksela. Na novodobijenu sliku primenjena je binarizacija na osnovu dobijenog HSV opsega i morfološke operacije - erozija i dilatacija, radi uklanjanja šuma.

2.1.3. Obrada baze za klasifikaciju ključnih tačaka
Baza ove mreže se sastoji od koordinata ključnih tačaka šake. Za njihovu detekciju korišćena je MediaPipe Holistic metoda, prilikom čije primene prag za detektovanje šake smanjen je sa 0.5 na 0.3 jer za određene položaje šake metod nije detektovao šaku. Na svaku sliku baze je pojedinačno primenjena detekcija ključnih tačaka i novodobijene slike su sačuvane u novu bazu. Nova baza je imala 42 parametra za svaku sliku:
- X - x koordinata svake tačke, ukupno 21
- Y - y koordinata svake tačke, ukupno 21
Formirana je još jedna baza, slična kao prva, za koju je korišćena je aproksimacija dubine koja je ugrađena u MediaPipe Holistic metodu. Ova aproksimacija daje po još jednu koordinatu za svaku tačku, stoga baza ima 63 parametra, po 3 za svaku tačku.
- X - x koordinata svake tačke, ukupno 21
- Y - y koordinata svake tačke, ukupno 21
- Z - dubina svake tačke, ukupno 21
2.2. kNN - k Nearest Neighboors
Binarizovana slika je podeljena na $N \times N$ mrežu, gde definišemo obeležje ($o$) svakog polja kao zasićenost, tj. udeo belih piksela unutar tog polja:
$$o = \frac{P_{bela}}{P_{polje}}$$
Pod pretpostavkom da su ovako dobijeni podaci podeljeni na klastere, potreban je način za njihovu klasifikaciju. Za ovo je korišćen kNN algoritam. Iz binarizovane baze podataka izdvojeno je po 6 slika za svaku klasu i njihova obeležja korišćena su kao definišuća baza podataka. Na prethodno fitovanim podacima, u Euklidskoj metrici je izračunata razdaljina između uzorka i svih primera definišuće baze, nakon čega je izabrano $k$ najbližih primera. Od tih $k$ primera klasifikator bira klasu koja se najčešće pojavljuje.

2.3. Keypoint Classification
Ovaj metod za cilj ima da klasifikuje sliku na osnovu koordinata ključnih tačaka šake. Kao klasifikator koristi fully connected čiji su ulaz koordinate ključnih tačaka, a izlaz jedna od 24 klase. Korišćena je jednostavna mreža sa četiri dense sloja. Metod je rađen sa i bez procene dubine ugrađene u MediaPipe Holistic metodu koja je korišćena za nalaženje ključnih tačaka.
2.4. Extended MNIST - CNN
Ovaj metod zasniva se na klasifikaciji pomoću konvolucione neuralne mreže. Model je građen po uzoru na konvolucioni klasifikacioni model za MNIST bazu podataka za ASL. Ova baza sadrži grayscale slike znatno manjih dimenzija od korišćene baze (28x28) pa je za adaptaciju modela za slike većih dimenzija sa tri umesto jednog kanala potrebno proširiti mrežu. Ovo proširenje postignuto je dodavanjem dodatna tri konvoluciona sloja i uklanjanjem dropout funkcija između slojeva radi manje osetljivosti pri treniranju.
2.5. EfficientNetB3
Za poboljšanje konvolucionih neuronskih mreža česta je praksa skaliranje po jednoj od sledeće tri dimenzije - dubina, širina i veličina slike. U 6 predložen je state-of-the-art način skaliranja mreže, u kome se dobija balans ove tri dimenzije skalirajući svaku od njih istom konstantom. Ovako je razvijeno osam mreža EfficientNetB0 do EfficientNetB7. Radi poklapanja rezolucije slika iz baze i ulaznih podataka mreže implementirana je EfficientNetB3 mreža.
3. Rezultati
3.1. kNN
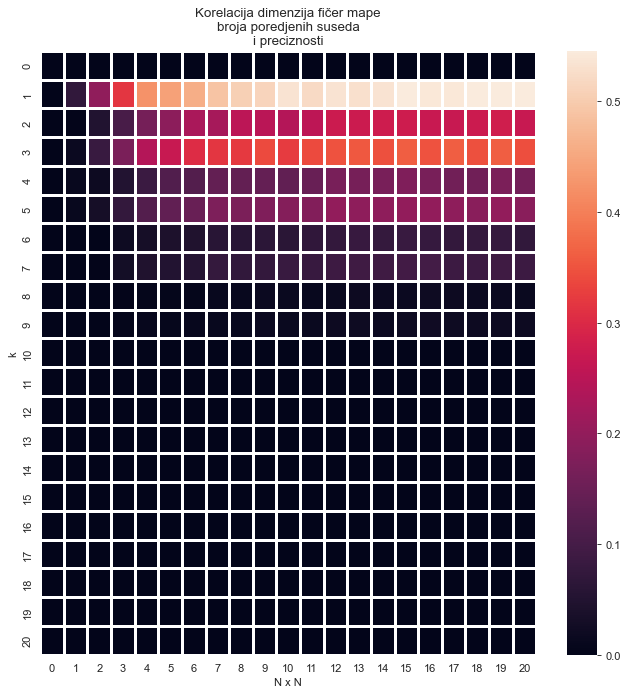
Na osnovu $N$ i $k$ parametara, izračunata je tačnost metode u svakom od slučajeva. Vizuelni prikaz rezultata je dobijen u vidu mape intenziteta. Ispostavlja se da preciznost raste srazmerno parametru $N$ i obrnuto srazmerno parametru $k$, pri čemu je najbolji rezultat dobijen za $k = 1$ i $N = 20$, sa preciznošću od 56%.
3.2. Keypoint Classification
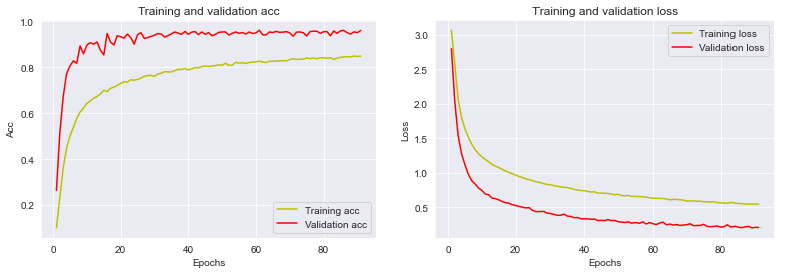
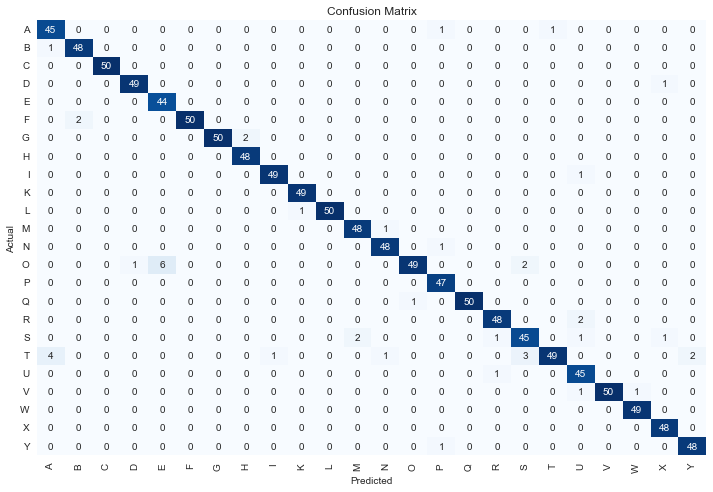
U slučaju kada je korišćena aproksimacija dubine dobijena je preciznost od 95.6%, dok je preciznost bez nje bila znatno manja, 85.8%. Razlika između ova dva primera verovatno bi bila primetnija u realnoj primeni kada nisu sve slike šaka na sličnoj udaljenosti od same šake. Grafici rezultata u daljem radu prikazani su samo za bolju od dve metode.
Matrica konfuzije predstavlja raspodelu učestalosti klasifikacije po klasama. Korisna je za primećivanje da li je neka klasa često pogrešno klasifikovana i kao šta. Na datoj matrici konfuzije najveća pogrešna vrednost je dobijena pripisivanjem slova „E” slovu „O” - šest puta.
3.3. CNN
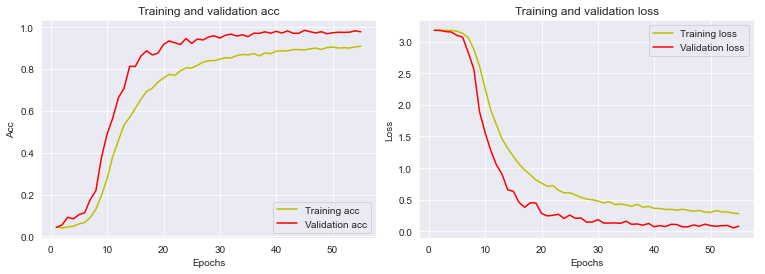
Ovako izmenjenom mrežom je dobijena preciznost od 96.25%. Iako precizniji od prethodnog metoda klasifikator za ovaj metod se znatno duže trenira.
3.4. EfficientNetB3
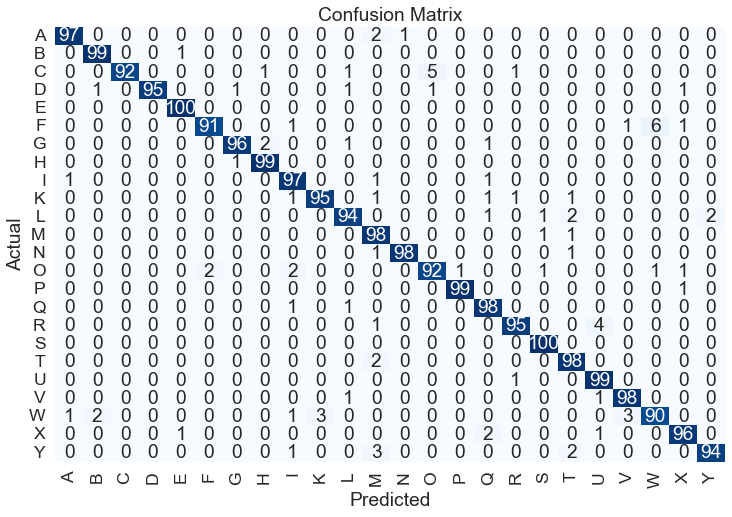
Korišćenjem EfficientNetB3 mreže dobijena je preciznost od 99%. Zbog kompleksnosti mreže njeno treniranje je izuzetno sporo.
4. Zaključak
Urađeno je poređenje metoda kNN, KC, CNN i EfficientNetB3 pri prepoznavanju američkog znakovnog jezika. Pokazalo se da je metodi kNN potrebno najviše dorade. Ova dorada bi primarno uključivala drugačiji sistem binarizacije šake kao i dublje ispitivanje raspodele klasa i da li se ključne tačke ASL-a uopšte raspoređuju po klasterima kao što je to slučaj za indijski znakovni jezik. Najbolju uspešnost je imala EfficientNetB3 metoda sa 99% tačnosti. Metode KC i CNN su imale visoke rezultate sa 95.6% i 96.25%, dok im je vreme treniranja bilo značajno kraće. Dalji rad na projektu bi uključivao skaliranje klasifikatora slike na video zapise. Ovaj problem donosi dodatan zadatak detektovanja lažnih znakova, trenutaka kada je šaka u kadru ali je u procesu pomeranja iz jednog znaka u drugi pa bi čitanje bilo kog slova bilo pogrešno. Ovaj problem rešava se kroz poređenje sigurnosti mreže u izabranu klasu kao i uvođenjem novih metrika kao latent cognizance priloženih u radu 3. Nakon uspešne implementacije klasifikatora na video snimke dodatno poboljšanje postiglo bi se implementacijom natural language processing modela pomoću kojih se mogu ukloniti nepreciznosti pri prevodu.
Literatura
-
K.Simonyan i A.Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition, arXiv:1409.1556, 2014. https://arxiv.org/abs/1409.1556 [pristupljeno 16.05.2025.] ↩︎
-
A. Sahu i S. Nandy, Real-time Indian Sign Language (ISL) Recognition, arXiv:2108.10970, 2021. https://arxiv.org/abs/2108.10970 [pristupljeno 16.05.2025.] ↩︎
-
D. N. Shah i N. A. Gajjar, Automatic Hand Sign Recognition: Identify Unusuality through Latent Cognizance, arXiv:2110.15542, 2021. https://arxiv.org/abs/2110.15542 [pristupljeno 16.05.2025.] ↩︎ ↩︎
-
Lexset, Synthetic ASL Alphabet, Kaggle dataset, 2021. https://kaggle.com/datasets/lexset/synthetic-asl-alphabet [pristupljeno 16.05.2025.] ↩︎
-
MediaPipe Holistic Solution, 2023. https://google.github.io/mediapipe/solutions/holistic.html [pristupljeno 2022.] https://github.com/google-ai-edge/mediapipe/blob/master/mediapipe/python/solutions/holistic.py [pristupljeno 16.05.2025.] ↩︎
-
M. Tan i Q. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, International Conference on Machine Learning (ICML), PMLR, 2019. https://arxiv.org/abs/1905.11946 [pristupljeno 16.05.2025.] ↩︎